Learning Beyond Labels
Self-Supervised Handwritten Text Recognition


Key Contributions
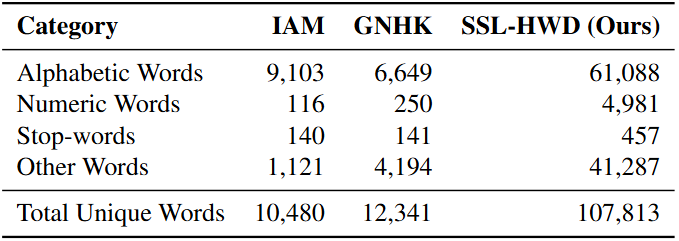
Massive Dataset
Introducing SSL-HWD: 10 million word-level images from 852 writers. A unified resource with 2.08M labeled and 7.92M unlabeled samples for scalable learning.
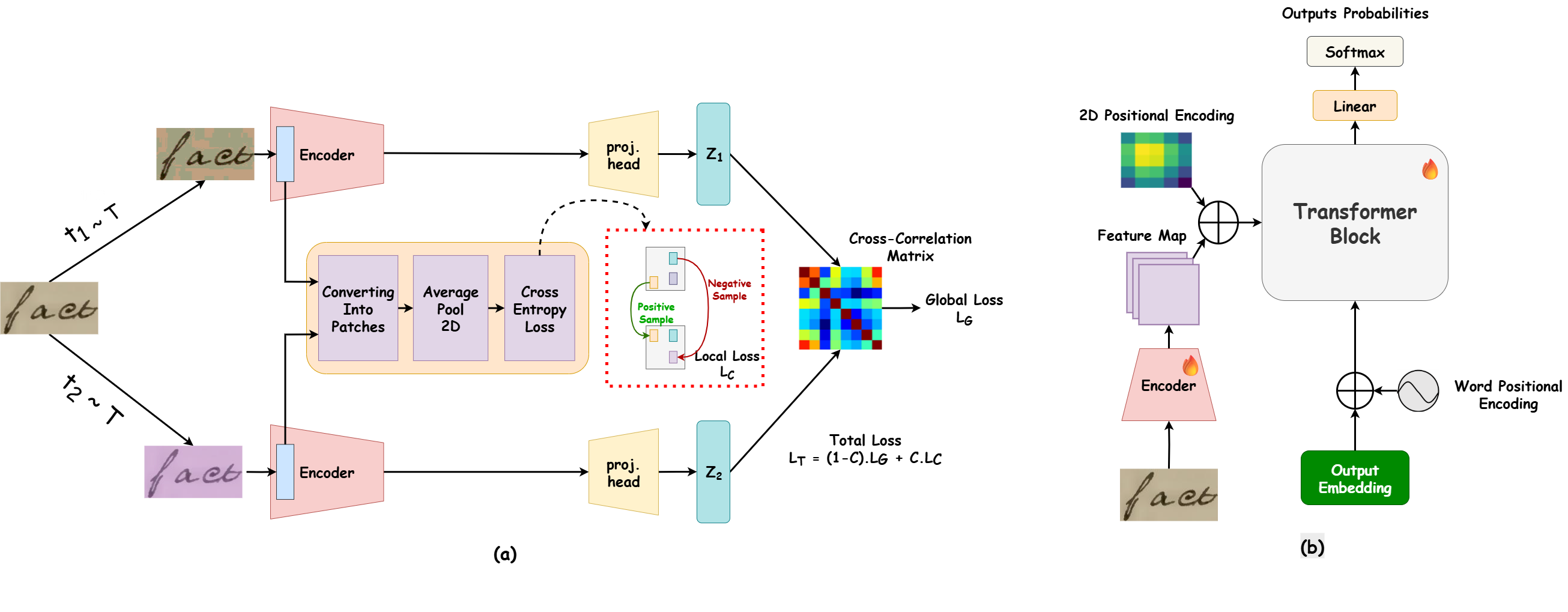
LoGo-HTR Framework
A novel two-stage strategy combining Local patch contrastive learning with Gobal decorrelation to learn robust, spatially discriminative features.
SOTA Performance
Outperforming baselines on IAM, GNHK, RIMES, & LAM. Achieving superior results even with limited amount of labeled data.
Abstract
This paper addresses a key challenge in Handwritten Text Recognition (HTR): the dependence on large volumes of labeled data. To overcome this, we propose a self-supervised learning (SSL) framework, LoGo-HTR, that minimizes labeling requirements while achieving strong recognition performance. We introduce a large-scale dataset, SSL-HWD, consisting of 10 million word-level handwritten images from diverse scanned documents, partitioned into a small labeled subset and a much larger unlabeled subset.
The LoGo-HTR framework combines a local contrastive loss for spatial consistency and a global decorrelation loss to enhance feature diversity. This dual objective enables robust, invariant, and spatially discriminative feature learning. Extensive experiments on standard HTR benchmarks, including multilingual and historical data, demonstrate that our method consistently outperforms state-of-the-art approaches, even when fine-tuned using only 20% of the available labeled training data.
Dataset Analysis
Proposed Framework
Quantitative Results
Comparison with State-of-the-Art
| Dataset | Model | #Params | SSL Pretrain | Training Data | WER / WRR | CER / CRR |
|---|---|---|---|---|---|---|
| IAM | TrOCRLARGE [34] | 558M | - | 100% | - / - | 2.89 / - |
| Bhunia et al. [5] | - | - | 100% | - / 86.0 | - / - | |
| Bluche et al. [6] | 750k/300k | - | 100% | - / - | 3.20 / - | |
| Michael et al. [39] | - | - | 100% | - / - | 4.87 / - | |
| HTR-VT [35] | 53.5M | - | 100% | 14.9 / - | 4.7 / - | |
| Gu et al. [23] | 80K | - | 100% | 10.32 / - | 3.36 / - | |
| LoGo-HTR (Ours) | 6.4M | Yes (Unlabeled) | 20% | 30.8 / 69.2 | 7.5 / 86.0 | |
| LoGo-HTR (Ours) | 6.4M | Yes (Unlabeled) | 40% | 19.3 / 80.7 | 5.2 / 91.0 | |
| LoGo-HTR (Ours) | 6.4M | Yes (Unlabeled) | 80% | 11.93 / 88.07 | 2.31 / 96.33 | |
| LoGo-HTR (Ours) | 6.4M | Yes (Unlabeled) | 100% | 10.27 / 89.73 | 2.01 / 97.76 | |
| GNHK | Lee et al. [33] | - | - | 100% | - / 50.2 | - / 86.1 |
| Mondal et al. [40] | - | - | 100% | - / 64.31 | - / 83.44 | |
| LoGo-HTR (Ours) | 6.4M | Yes | 20% | 32.1 / 67.9 | 19.4 / 84.3 | |
| LoGo-HTR (Ours) | 6.4M | Yes | 100% | 12.07 / 87.93 | 7.20 / 92.58 | |
| RIMES | Bhunia et al. [5] | - | - | 100% | - / 90.06 | - / - |
| SPAN [12] | 19M | - | 100% | 13.8 / - | 3.81 / - | |
| Gu et al. [23] | 80K | - | 100% | 6.63 / - | 2.19 / - | |
| LoGo-HTR (Ours) | 6.4M | Yes | 20% | 26.50 / 73.50 | 6.68 / 93.20 | |
| LoGo-HTR (Ours) | 6.4M | Yes | 100% | 5.50 / 94.50 | 1.78 / 98.05 | |
| LAM | TrOCR [7, 34] | 385M | - | 100% | 11.6 / - | 3.6 / - |
| OrigamiNet [7, 57] | 115.3M | - | 100% | 11.0 / - | 3.0 / - | |
| HTR-VT [35] | 53.5M | - | 100% | 7.4 / - | 2.8 / - | |
| LoGo-HTR (Ours) | 6.4M | Yes | 20% | 24.86 / 74.8 | 7.6 / 92.9 | |
| LoGo-HTR (Ours) | 6.4M | Yes | 100% | 6.3 / 93.1 | 2.39 / 97.33 |
Cross-Dataset Evaluation
| Finetune Source | Test Datasets (WER / CER) | ||||
|---|---|---|---|---|---|
| IAM | GNHK | RIMES | LAM | OURS | |
| IAM | 10.27 / 2.01 | 52.50 / 47.80 | 21.50 / 11.8 | 27.52 / 12.38 | 26.70 / 18.20 |
| GNHK | 34.20 / 22.90 | 12.07 / 7.20 | 36.00 / 23.50 | 25.00 / 12.00 | 19.40 / 12.60 |
| RIMES | 18.30 / 9.40 | 50.08 / 43.9 | 5.50 / 1.78 | 22.4 / 8.6 | 25.50 / 16.90 |
| LAM | 24.30 / 9.10 | 28.00 / 13.50 | 22.90 / 7.50 | 6.9 / 2.39 | 16.00 / 7.20 |
| Ours (LoGo) | 13.20 / 2.90 | 10.10 / 6.80 | 11.20 / 3.50 | 16.40 / 7.20 | 5.20 / 1.20 |
Qualitative Results

Citation
@article{mitra2025learning,
author = {Mitra, Shree and Mondal, Ajoy and Jawahar, C.V.},
title = {Learning Beyond Labels: Self-Supervised Handwritten Text Recognition},
journal = {WACV},
year = {2026},
}